AI Decision Tree: What It Is, How It Works, and Real-World Applications

Decision trees represent one of the most intuitive and widely used approaches in artificial intelligence and machine learning. Unlike complex neural networks that function as mysterious black boxes, decision trees mirror how humans naturally make decisions—by asking a series of questions and following logical paths based on the answers. This transparency makes them valuable both as machine learning models that computers can train automatically and as frameworks for understanding and structuring human decision-making in operational environments.
- What Is an AI Decision Tree?
- How AI Decision Trees Work
- Training an AI Decision Tree Model
- Types of AI Decision Trees
- When to Use an AI Decision Tree
- Advantages and Limitations of AI Decision Trees
- Explainability and Decision Trees in AI
- Can AI Create a Decision Tree?
- Applying AI Decision Tree Principles Beyond Machine Learning
- Guided Decision Trees in Customer Support and Call Centers
- Operational Decision Trees and Process Shepherd
- AI Decision Trees in a Process-Driven Future
This guide explains what AI decision trees are from a technical perspective, how they function as machine learning models, their advantages and limitations, and how the decision tree concept extends beyond pure AI into practical applications where humans and intelligent systems work together to make consistent, explainable decisions at scale.
What Is an AI Decision Tree?
An AI decision tree is a supervised machine learning model that uses a tree-like structure of decisions and their possible consequences to make predictions or classifications. The model learns patterns from training data, then applies those patterns to new situations by following branches through the tree based on input features until reaching a final prediction at a leaf node.
In supervised learning, the model trains on labeled examples where both the input features and correct outcomes are known. For classification tasks, decision trees predict which category something belongs to—whether an email is spam or legitimate, whether a loan applicant represents high or low risk, or whether a medical test indicates disease. For regression tasks, they predict numerical values like house prices, temperature forecasts, or customer lifetime value.
The tree structure consists of a root node where evaluation begins, internal decision nodes that test specific features or conditions, branches representing possible outcomes of those tests, and leaf nodes containing final predictions or classifications. A simple example might classify whether to approve a loan: the root node checks credit score, branches split based on whether it’s above or below a threshold, subsequent nodes examine income and debt levels, and leaf nodes output “approve” or “deny” decisions.
This straightforward structure makes AI decision trees particularly valuable when explainability matters—when humans need to understand why the model made specific predictions rather than just trusting outputs from opaque systems.
How AI Decision Trees Work
Understanding the mechanics of how decision trees operate reveals both their power and their limitations as machine learning models.
Core Components of a Decision Tree
The root node serves as the entry point where all predictions begin. It represents the first question or feature test that the model uses to begin classification or prediction. The root node splits data into subsets based on the feature that provides the most information gain—the characteristic that best separates different outcomes in the training data.
Decision nodes (also called internal nodes) appear throughout the tree wherever additional questions or tests occur. Each decision node evaluates a specific feature—checking whether a value exceeds a threshold, matches a category, or falls within a range—and determines which branch to follow next.
Branches connect nodes, representing the possible outcomes of tests performed at decision nodes. A binary tree has two branches from each decision node (yes/no, above/below threshold), while multi-branch trees can have multiple paths representing different categorical values or ranges.
Leaf nodes (also called terminal nodes) contain the final predictions or classifications. When the model reaches a leaf node, it outputs whatever value that leaf represents—a category for classification problems or a numerical prediction for regression tasks. No further splitting or testing occurs at leaf nodes.
How Decisions Are Made
Decision trees make predictions through systematic feature evaluation and path traversal. When new data requires classification or prediction, the model begins at the root node and evaluates the first feature. Based on that evaluation, it follows the appropriate branch to the next decision node.
Feature selection at each node chooses which characteristic to test based on how effectively it separates the data. Various algorithms determine optimal features, typically aiming to maximize information gain or minimize impurity. Common splitting criteria include Gini impurity, which measures how mixed the classes are within each subset, and entropy, which quantifies the disorder or uncertainty in the data.
The model continues this path traversal from root to outcome, evaluating features and following branches until reaching a leaf node. The path taken through the tree represents the specific combination of feature values that led to the final prediction, making the reasoning transparent and traceable.
For example, a decision tree predicting customer churn might first check account age, then examine usage frequency for long-term customers while checking complaint history for newer customers. Each customer follows a unique path based on their specific characteristics, ultimately reaching a leaf node predicting whether they’re likely to leave or stay.
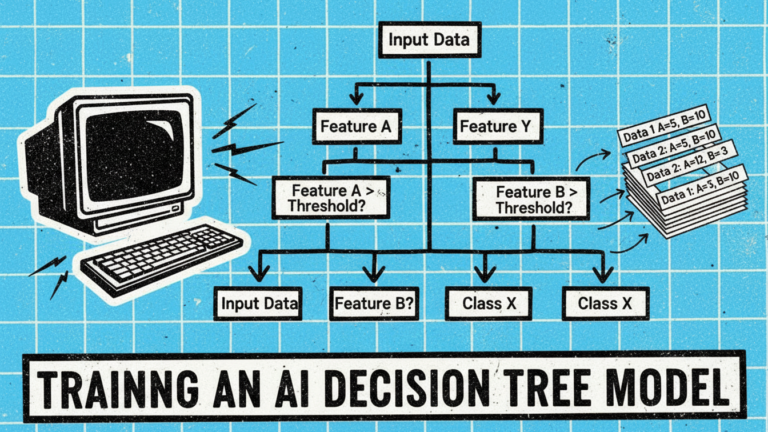
Training an AI Decision Tree Model
AI decision trees don’t emerge fully formed—they learn structure and decision rules from training data through systematic analysis.
The supervised learning setup requires a dataset containing both input features (the characteristics used for prediction) and labeled outcomes (the correct answers for those examples). For a medical diagnosis tree, training data might include patient symptoms, test results, and confirmed diagnoses. For loan approval, it would contain applicant information and whether loans were repaid or defaulted.
During training, the algorithm analyzes this data to determine optimal splitting points at each node. It evaluates all possible features and thresholds, calculating which splits best separate different outcomes. The tree grows recursively, creating new decision nodes and branches until reaching stopping criteria like maximum depth, minimum samples per leaf, or when further splitting provides negligible improvement.
Training data and labeled outcomes quality directly impacts model performance. Insufficient training examples, biased samples, or incorrect labels lead to poor decision trees that don’t generalize well to new data. The model essentially memorizes patterns from training examples, so those patterns must accurately represent the real-world situations where predictions will be applied.
Overfitting versus generalization represents a critical challenge. Overfitting occurs when trees grow too complex, capturing noise and anomalies in training data rather than genuine patterns. An overfitted tree performs excellently on training examples but poorly on new data because it learned specifics of the training set rather than general principles.
Pruning addresses overfitting by simplifying trees after or during training. Pre-pruning stops tree growth early by setting maximum depth or minimum samples required for splitting. Post-pruning allows full tree growth, then removes branches that don’t improve performance on validation data. Both approaches trade some training accuracy for better generalization to new situations.
Types of AI Decision Trees
Decision trees come in several varieties based on their prediction tasks and structure.
Classification trees predict categorical outcomes—discrete classes or labels. They answer questions like “which category does this belong to?” Examples include spam detection (spam or not spam), disease diagnosis (which condition, if any), customer segmentation (which demographic group), or fraud detection (fraudulent or legitimate).
Classification trees typically use metrics like Gini impurity or entropy to determine splits, aiming to create pure leaf nodes where all examples belong to the same class. The prediction at each leaf represents the most common class among training examples that reached that node.
Regression trees predict continuous numerical values rather than categories. They answer questions like “what will the value be?” Examples include predicting house prices based on features like size and location, forecasting sales revenue, estimating delivery times, or projecting customer lifetime value.
Regression trees use different splitting criteria than classification trees, often minimizing variance or mean squared error within leaf nodes. Predictions at leaf nodes typically represent the average value of training examples that reached that node.
Binary versus multi-branch trees differ in structure. Binary trees split each decision node into exactly two branches, creating simpler, more balanced structures. Multi-branch trees can split into multiple paths simultaneously, which can be more intuitive for categorical features with many values but creates more complex structures.
Binary trees are more common in machine learning implementations because they’re computationally simpler and many algorithms naturally produce binary splits. Multi-branch trees appear more often in business rule systems and human-designed decision frameworks where splitting into many categories makes logical sense.
When to Use an AI Decision Tree
Decision trees suit specific situations better than other machine learning approaches. Understanding these ideal use cases helps select appropriate models.
Problems requiring explainability benefit enormously from decision trees. When stakeholders need to understand why the model made specific predictions—for regulatory compliance, building trust, or debugging issues—decision trees provide clear reasoning paths. You can literally trace which features led to each prediction, unlike neural networks where internal reasoning remains opaque.
Structured data where examples have clear features and values works well with decision trees. Tabular data with columns representing distinct characteristics fits naturally into the decision tree framework. Image data, natural language, or unstructured information typically requires different approaches, though decision trees can operate on features extracted from these sources.
Rule-based decision logic that humans can articulate and understand aligns with how decision trees operate. If domain experts can describe decision-making as a series of questions and thresholds, decision trees can likely learn similar logic from data. Situations where decisions follow clear rules rather than subtle patterns favor decision trees over more complex models.
Moderate data complexity where relationships between features and outcomes are relatively straightforward but not trivial suits decision trees. Extremely simple problems might not need machine learning at all, while highly complex relationships with intricate interactions between many features might require ensemble methods or deep learning.
Decision trees also work well when training data is limited, when features have mixed types (numerical, categorical, ordinal), and when fast prediction speed matters since evaluating a tree is computationally inexpensive compared to complex models.
Advantages and Limitations of AI Decision Trees
Like all machine learning approaches, decision trees have distinct strengths and weaknesses that determine their appropriate use.
Advantages
Interpretability stands as the primary advantage. Decision trees create transparent models where predictions can be explained through the path taken from root to leaf. Stakeholders without machine learning expertise can understand the logic, verify it makes sense, and identify potential biases or errors in reasoning.
Transparency supports accountability, particularly important in high-stakes domains like healthcare, criminal justice, or financial services. When models make decisions affecting people’s lives, being able to explain why builds trust and enables meaningful oversight.
Minimal data preparation simplifies implementation since decision trees handle mixed data types naturally, don’t require feature scaling, and tolerate missing values reasonably well. Unlike neural networks requiring extensive preprocessing, decision trees can work with raw tabular data directly.
Human-readable logic allows domain experts to review and validate model reasoning. A medical professional can examine a diagnostic tree to ensure it aligns with clinical knowledge. A financial analyst can verify a credit scoring tree reflects sound risk assessment principles.
Limitations
Overfitting occurs easily with decision trees. Without constraints, trees grow to perfectly classify training data by creating overly specific rules that don’t generalize. This makes regularization through pruning or depth limits essential but requires careful tuning.
Instability means small changes in training data can produce dramatically different trees. Adding or removing a few examples might completely reorganize the tree structure, making decision trees sensitive to data quality and sampling variations.
Lower accuracy versus ensembles limits single decision trees when prediction performance is paramount. Random forests, gradient boosting, and other ensemble methods that combine multiple trees typically outperform individual trees substantially, though at the cost of reduced interpretability.
Scalability challenges emerge with very large feature sets or highly complex decision boundaries. Trees can become unwieldy, and training time grows significantly. Deep trees also become harder to interpret despite their theoretical transparency.
These limitations explain why decision trees often serve as building blocks for more sophisticated ensemble methods rather than being used individually in production machine learning systems. However, their interpretability advantage remains relevant for applications where understanding predictions matters more than achieving maximum accuracy.
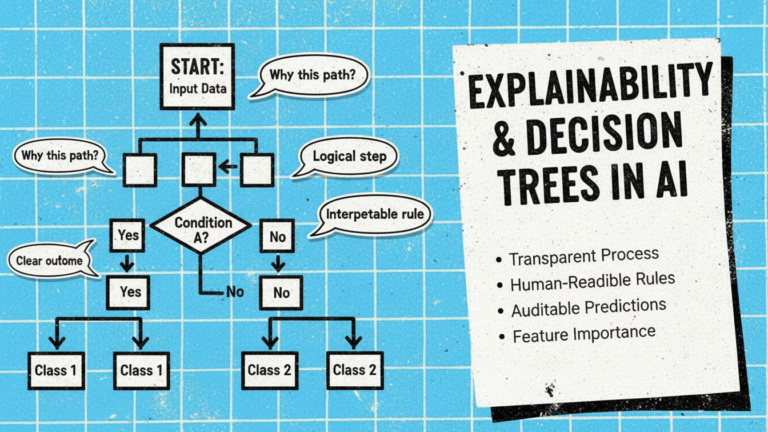
Explainability and Decision Trees in AI
The growing emphasis on explainable AI (XAI) has renewed interest in decision trees and similar transparent models.
Why explainability matters extends beyond intellectual curiosity. Regulatory frameworks increasingly require organisations to explain automated decisions, particularly when affecting individuals. The European Union’s GDPR includes a “right to explanation” for algorithmic decisions. Financial regulations require transparent credit scoring. Healthcare applications need interpretable diagnostics to support clinical judgment rather than replace it.
Decision trees versus black-box models represents a fundamental trade-off. Complex models like deep neural networks often achieve higher accuracy but provide little insight into their reasoning. Decision trees sacrifice some accuracy for transparency, creating models humans can understand, verify, and trust.
Regulatory and ethical relevance make explainability increasingly non-negotiable. When AI systems make mistakes, stakeholders need to understand why to prevent recurrence. When models exhibit bias, transparency enables identification and correction. When predictions affect people’s lives—loan approvals, medical diagnoses, criminal sentencing—ethical considerations demand explainable reasoning.
Decision trees don’t solve all explainability challenges. Very deep or complex trees can become difficult to comprehend despite their theoretical transparency. However, they provide baseline interpretability that makes them valuable when model understanding matters as much as prediction accuracy.
Can AI Create a Decision Tree?
A common question about decision trees involves whether AI systems can generate them automatically or whether humans must design each tree manually.
AI systems can absolutely create decision trees automatically through machine learning algorithms. Given training data with input features and labeled outcomes, decision tree algorithms analyze the data, determine optimal splitting points, grow the tree structure, and produce final models without human intervention beyond setting initial parameters and constraints.
This automatic generation distinguishes AI decision trees from manually designed decision flowcharts. The algorithm discovers patterns in data that might not be obvious to humans and constructs tree structures optimized for predictive accuracy on that specific dataset.
However, humans still define critical aspects of the process. They select which features the model can use, establish constraints like maximum depth or minimum samples, determine stopping criteria and pruning strategies, and most importantly, define goals and validate that learned trees make sense.
The difference between model creation and decision governance is important. While AI can learn decision trees from data, humans must ensure those learned models align with domain knowledge, don’t perpetuate biases, and remain appropriate for their intended use. Automated tree generation doesn’t eliminate the need for human judgment about whether learned patterns should guide real decisions.
Applying AI Decision Tree Principles Beyond Machine Learning
An AI decision tree isn’t just a machine learning model—it represents a broader framework for structuring any decision-making process through logical, explainable steps.
Beyond machine learning, decision tree concepts apply wherever decisions follow structured logic that can be represented as questions, conditions, and outcomes. Business process design uses decision tree thinking to map workflows. Troubleshooting guides follow decision tree structures to diagnose problems systematically. Compliance procedures use decision trees to ensure required steps occur in proper order.
Decision trees as universal decision frameworks work because they mirror natural human reasoning. We instinctively ask questions, evaluate answers, and adjust our approach based on responses. Formalizing this intuitive process into explicit tree structures creates consistency and clarity at scale.
Human-in-the-loop decision environments benefit particularly from structured decision trees. When people must make complex decisions quickly—customer service agents troubleshooting issues, medical professionals diagnosing conditions, financial advisors recommending products—decision trees provide consistent frameworks without removing human judgment entirely.
The key distinction is between AI systems learning decision trees from data versus humans designing decision trees to guide operational work. Both applications use the same fundamental structure of nodes, branches, and outcomes, but serve different purposes. Machine learning trees automate predictions; operational decision trees guide human execution.
Guided Decision Trees in Customer Support and Call Centers
Customer support and call center environments illustrate how decision tree principles apply to real-time human decision-making under pressure.
Real-time decision pressure creates challenges for support agents. Customers expect immediate help, leaving no time to consult lengthy documentation or seek supervisor guidance. Agents must diagnose problems, determine appropriate solutions, follow required procedures, and provide consistent service—all during live conversations where delays damage customer experience.
Knowledge fragmentation compounds these challenges. Information agents need sits scattered across knowledge bases, policy documents, training materials, and institutional memory. Finding relevant information quickly while maintaining conversation flow proves difficult, leading to inconsistent service when different agents access different information or interpret guidelines differently.
Training challenges emerge because complex support requires agents to handle diverse scenarios, many encountered infrequently. Memorizing every possible situation and correct response isn’t realistic. Traditional training provides general principles but can’t prepare agents for every specific case they’ll face.
Need for structured guidance becomes clear when examining support operations. Agents benefit from decision trees that guide them through complex processes step-by-step, present relevant questions based on customer situations, provide clear next actions at each point, and ensure consistent service regardless of individual agent experience.
These operational decision trees don’t learn from data like machine learning models. Instead, they codify expert knowledge and organizational procedures into structures that guide agents toward correct decisions during actual customer interactions.
Operational Decision Trees and Process Shepherd
The gap between decision tree concepts and operational execution creates opportunities for platforms designed specifically to guide human decision-making in real time.
Process Shepherd enables organizations to create and deploy guided workflow decision trees that support agents during live customer interactions. Rather than static flowcharts or documentation that agents must interpret, Process Shepherd provides interactive decision trees that present questions, evaluate responses, and automatically determine next steps based on specific situations.
For call centers and support operations, this means agents follow structured paths through complex troubleshooting, compliance procedures, or service scenarios without memorizing every detail. The platform applies explainable decision logic—the same transparency that makes AI decision trees valuable—to ensure agents understand why they’re taking specific actions rather than blindly following instructions.
Process Shepherd helps agents navigate complex customer issues by breaking down sophisticated processes into manageable steps, adapting guidance based on customer responses and account details, enforcing required procedures like verification or disclosure steps, and maintaining consistency across teams, shifts, and experience levels.
This application bridges AI theory and operational execution. The decision tree structure—nodes, branches, conditions, outcomes—provides the framework. The implementation focuses on guiding human agents rather than automating predictions. The result combines machine precision in executing logic with human judgment in applying that logic appropriately to unique customer situations.
For organizations managing support operations at scale, operational decision trees transform tribal knowledge into executable systems, reduce training time by providing real-time guidance, ensure compliance by embedding requirements into workflows, and create the consistency that defines quality service.
AI Decision Trees in a Process-Driven Future
Decision trees represent enduring concepts in both artificial intelligence and practical decision-making. Their fundamental structure—asking questions, evaluating conditions, following logical paths to outcomes—mirrors human cognition and remains relevant regardless of technological advances.
From the machine learning perspective, decision trees continue evolving. Ensemble methods like random forests and gradient boosting extend basic decision trees to achieve state-of-the-art performance on many problems. Research into interpretable AI keeps decision tree transparency relevant as model explainability grows increasingly important for regulatory, ethical, and practical reasons.
From the operational perspective, decision tree thinking increasingly structures how organizations approach complex processes requiring consistent execution. The same logical framework that makes decision trees valuable in machine learning makes them valuable for guiding human work through structured, explainable steps.
Growing importance of explainability ensures decision trees remain relevant. Whether in AI models that must justify predictions or operational systems that guide human decisions, transparency matters. Understanding why specific decisions occur—whether made by algorithms or people following processes—builds trust, enables improvement, and satisfies accountability requirements.
Human-AI collaboration through guided decisions represents the synthesis. AI systems can learn decision trees from data, discover patterns humans might miss, and automate predictions at scale. Operational decision trees can guide humans through complex situations requiring judgment, empathy, and flexibility. Together, these approaches create systems where artificial and human intelligence complement each other—machines handling automation and pattern recognition, humans applying context and wisdom, both following explainable logic that stakeholders can understand and trust.
The future isn’t purely automated decision-making or purely manual processes. It’s intelligent systems where decision tree principles provide common frameworks—transparent, explainable, and effective—that work whether executed by algorithms, guided humans, or combinations of both working together toward consistent, quality outcomes.

